
Abstract
Biometrics has been evolving as an exciting yet challenging area in the last decade. Though face recognition is one of the most promising biometrics techniques, it is vulnerable to spoofing threats. Many researchers focus on face liveness detection to protect biometric authentication systems from spoofing attacks with printed photos, video replays, etc. As a result, it is critical to investigate the current research concerning face liveness detection, to address whether recent advancements can give solutions to mitigate the rising challenges. This research performed a systematic review using the PRISMA approach by exploring the most relevant electronic databases. The article selection process follows preset inclusion and exclusion criteria. The conceptual analysis examines the data retrieved from the selected papers. To the author, this is one of the foremost systematic literature reviews dedicated to face-liveness detection that evaluates existing academic material published in the last decade. The research discusses face spoofing attacks, various feature extraction strategies, and Artificial Intelligence approaches in face liveness detection. Artificial intelligence-based methods, including Machine Learning and Deep Learning algorithms used for face liveness detection, have been discussed in the research. New research areas such as Explainable Artificial Intelligence, Federated Learning, Transfer learning, and Meta-Learning in face liveness detection, are also considered. A list of datasets, evaluation metrics, challenges, and future directions are discussed. Despite the recent and substantial achievements in this field, the challenges make the research in face liveness detection fascinating.
Keywords: artificial intelligence (AI); domain adaptation; explainable AI (XAI); face liveness detection (FLD)
Biometric authentication has consistently outperformed conventional password-based authentication schemes [1]. Personal identification was limited in prehistoric times. Today, computer vision and biometrics can distinguish people without credentials or artifacts [2]. Biometrics can identify people instead of their affiliations, belongings, or confidential information. The need for accurate and machine-based identification led us to biometrics, which uses technology to speed up the process of identifying and authenticating people. The printed IDs have been replaced with biometric IDs, which allow for proof of ‘who you are’ without carrying a card or other document [3].
Verification is a crucial step in granting authorized users access to the resources. Conventional authentication solutions, which include a PIN, card, and password, cannot distinguish between legitimate users and impostors who accessed the system fraudulently [1,2]. There are numerous chances of forgetting the password/PIN or losing or misplacing the card. A biometric system is a device that enables the automatic identification of an individual. There is no need to memorize a password, card, or PIN code because the biometric authentication system is simple to use [4].
Biometrics have been intensively researched for their automation, accessibility, and precision in meeting the increasing security demands of our daily life. As the technology has evolved through monitoring crime identification and forensics, it is a machine that analyzes human individuals’ physiological and behavioral characteristics [5] to classify them uniquely. As per a report by (www.statista.com (accessed on 16 January 2023)), the market of contactless biometrics would reach 37.1 billion USD whereas, by 2028, the face-based biometric recognition market would reach USD 12.11 billion due to promising applications in diverse categories, as given in the “Facial Recognition Business” report [6]. Biometrics has been effectively implemented in several areas where security is a top priority. For instance, personal identity cards for airport check-in and check-out, confidential data from unauthorized individuals, and credit card validation.
Several biometric features, including fingerprint, iris, palm print, and face, are utilized for recognition and authentication. Face-based authentication provides more secure contactless authentication of the user than fingerprints and iris. Table 1 exhibits numerous facial biometric detection application domains.
Table 1. Several application domains for facial biometric detection.
However, one of the biometric recognition systems’ most significant challenges is deceptive identification, widely known as a spoofing attack [13]. Submitting a facial artifact of a legitimate user could easily construct using a person’s face photos or videos from a “public” social media platform; an impostor can quickly access an insecure face recognition system. In general, also referred to as presentation attacks, these are straightforward, easy to implement, and capable of fooling face recognition (FR) systems and providing access to unauthorized users. These are becoming critical threats in advanced biometric authentication systems. Effective face liveness detection systems are increasingly attracting more attention in the research community, and several challenges make it difficult.
A few biometric traits evolved as the field progressed and occasionally disappeared. To be sure, face recognition is one biometric characteristic that has stood the test of time. Face characteristics are distinctive. Face-based authentication offers a more reliable yet contactless user identity than iris and fingerprint scanning. Face biometrics, which provides a secure identity and forms the basis of an inventive biometric system, has thus emerged as the preferred study area. However, printed face images or other artifacts can be used to fake invader challenges on face biometric systems, making them highly vulnerable. Spoofed faces can stop the face recognition system from working correctly. Various researchers concentrate on identifying facial liveness to prevent attacks on the biometric system.
Therefore, it is crucial to categorize the current research on the biometric of Face liveness detection to address how growing technologies might provide explanations to lower the emerging hazards. Facial recognition-based applications have made tremendous progress due to artificial intelligence (AI) techniques. Deep learning has advanced in recent years [14,15,16]. The use of artificial neural networks or convolutional neural networks (CNNs) in many computer vision tasks [17,18,19] has been extensively studied [20], especially with the advancement of robust hardware and enormous data sets. Image categorization and object detection were successfully solved using CNNs [21]. The existing body of literature on Face liveness detection concentrates on advances in hardware and software and various categorization methods employing ML- and DL-based methodologies. It is essential to do a comparative examination of these procedures based on several assessment criteria. It is necessary to thoroughly examine the pertinent articles and academic publications to understand what research has been directed toward biometric and face liveness detection. This study seeks to provide information on a range of datasets, performance metrics, face spoofing attacks, and methods for detecting the liveness of a face.
Fingerprints and other biometric features were used in previous biometric identification research. Semi-automated facial recognition systems that were distinctive to each person were initially proposed in 1988. Early in 2010, a face-liveness detecting algorithm was created. Since 2013, Face Liveness Detection (FLD) research has extensively used machine learning (ML) technologies.
The potential of ML to forecast and classify data is a key justification for using these algorithms. The face-liveness identification techniques include logistic regression, SVM, AdBoost, and Random Forest. The progress of face biometric authentication is seen in Figure 1. Huge volumes of information are processed using deep learning (DL) algorithms. The researchers started utilizing deep learning technology when facial liveness detection algorithms were introduced. Researchers have adopted DL methods for face liveness identification because they offer superior features to conventional handmade features. Some academics began working on the pre-trained networks used for face liveness detection, including convolutional neural networks (CNN), ResNet50, Inception model, VGG16, VGG19, GoogleNet, and AlexNet [20,22,23].

Figure 1. Progression of face liveness detection systems.
To uncover research trends and gaps in face liveness detection on face recognition (FR) systems, a systematic literature review (SLR) is necessary. This paper critically examines existing studies on face liveness detection and uses insights to develop new directions to achieve this goal.
Very few systematic literature review (SLR) papers are available on face liveness detection as per the authors’ knowledge. One of the most recent review papers based on face anti-spoofing methods with generic consumer devices (RGB cameras) was by Ming et al. [24]. In this work, the authors discussed the typology of PAD methods, various databases available for 2D and 3D attacks, key obstacles, evolutions, and recent developments in face liveness detection and prospects. To the author’s knowledge, this work gives valuable insight to researchers interested in using face anti-spoofing methods.
Thepade et al. [25] reviewed face anti-spoofing techniques comprehensively. Here, the authors discussed the texture, motion, multi-fusion-based face anti-spoofing methods, and available 2D attack databases. It also describes various face anti-spoofing techniques, including CNN, texture feature descriptors, and motion-based techniques. However, additional study is required to establish a reliable face biometric system.
Zhang et al. have done a review of the face anti-spoofing algorithm [26]. In this work, the authors show the progress of face spoofing techniques based on manual feature extraction methods based on image texture, image quality, computer interaction, and depth analysis. Then, deep learning automatically features extract, transfer learning, feature integration, and domain generalization. In 2019, a systematic literature review on insights into face liveness detection by Raheem et al. [27]. It focuses mainly on liveness indicators as a hint that helps devise a suitable solution for face spoofing problems. The paper [28] gives a comprehensive study of the state-of-the-art methods for PAD and an overview of respective labs working in this domain. Challenges and competitions in this domain are discussed in detail.
However, this paper considers a research study from 2011 to 2017. In 2021, another competition for face liveness detection (LivDet-Face2021) was conducted through Biometric Evaluation and Testing (BEAT) platform. Competition has opened several challenges to be solved by researchers [29]. In the paper, a review of the face presentation attack competition is conducted. Detail study of the various competition’s opened in this domain from 2019 to 2021 is discussed, along with future challenges.
However, more existing review papers are focused on only one aspect, such as deep learning-based unimodal and multi-modal approaches [30], sensor-based approaches [31], 3D mask presentation attack detection under thermal infrared conditions [32], presentation attack detection methods for smartphones [33], various feature extraction techniques, performance metrics for detection of morph attacks [34], deep learning–based face presentation attack detection, bibliometric review of domain adaptation–based face presentation attacks detection [35] There have been few researchers that have examined feature extraction approaches and datasets available for face liveness identification.
No existing systematic review focuses on unseen presentation attack detection challenges and problems. The current systematic literature review focuses solely on a single topic, such as deep learning-based techniques, and lacks a thorough evaluation based on publicly accessible datasets. A thorough examination of the methods employed for effective and dependable face anti-spoofing systems is also lacking in the literature. Prior research relevant to this study is listed in Table 2.
Table 2. Prior research related to FLD.
Our SLR comprehensively presents the most recent advancements related to face liveness detection by undertaking thorough surveys on machine learning-based and deep learning-based techniques and using publicly available datasets and evaluation metrics. This systematic review aims to critically examine existing research articles and their outcomes in the formulated research issue.
This research paper presented a systematic literature review (SLR) that, to the author’s knowledge, is one of the foremost to cover the face liveness detection methods based on the AI approach for robust face recognition.
This study aims to compare the current biometric face liveness detection methods and to review the results of the most recent investigations. As a result, research questions are presented to analyze face liveness detection comprehensively. The research questions were developed, as shown in Table 3, to enhance the comprehensiveness of this systematic literature review study.
Table 3. Research Goals.
The contributions of our systematic literature review are as follows:
This SLR has some obvious risks to its logic, regardless of whether or not the appropriate keywords were detected or relevant search engines were chosen. In this regard, a list of distinct publications demonstrates that the search scope is acceptable since no other papers were discovered to meet the specified inclusion criteria. Although it is expected, our SLR may have missed some relevant research due to the limitations of the scientific dataset, specific keywords employed in the search, and review duration. From 2010 through 2022, the author chooses only 95 studies. Authors were confident in the manual screening of studies obtained from “library services such as SCOPUS and WoS (Web of Science).”
The remaining sections of the paper are structured as follows: Section 2 discusses the proposed methodology. The findings and solutions to the submitted study questions are presented in Section 3. Section 4 examines the methods covered in a previous section, followed by Section 5, in which evaluation metrics are discussed. Section 6 and Section 7 portray the challenges and future directions for face liveness detection. Section 8 is on discussion followed by conclusions. The outline of this SLR is represented in Figure 2.
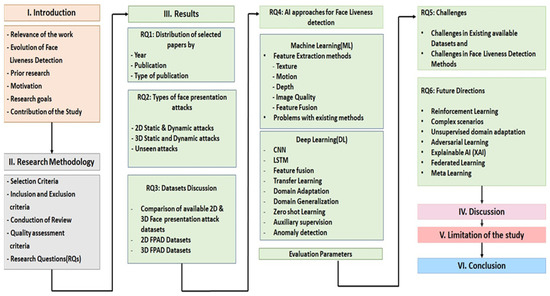
Figure 2. Outline of SLR.
A systematic review was carried out using the Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) process. A set of guidelines for conducting systematic reviews and other data-driven meta-analyses are given in PRISMA Approach [37]. The conduct of a systematic review three steps protocol is used in this paper: the formulation of research questions, the search databases, and the criteria for inclusion and exclusion of research articles—the details of these steps for research analysis are detailed in the following pages [38]. This systematic review is organized to cover the study’s breadth under consideration by categorizing and evaluating existing publications. The first step is to define the research questions so that the coverage rate of current works is accurately described. There should be some perspectives that can help researchers generate new ideas by analyzing similar results. Table 3 lists the research questions used in SR Research question 1 aims to review the published work. The purpose of research question 2 is to list all possible attacks on face presentation. The detailing of the available datasets explored in FPAD is addressed with research question 3. A few prominent FPAD methods are to be studied in research question 4. The limitations and challenges of existing prominent methods have to be listed in research question 5. Future work and progress directions are expected to be chalked out in research question 6. The first step in conducting SR is to identify information sources.
Related manuscripts were found using the most popular Scopus and Web of Science. The next step is to develop procedures for reviewing the technical and scientific articles that these searches produced to identify relevant papers. The proposed approach is divided into two phases. The first phase uses Boolean operators AND/OR to identify search terms from research questions and prepare a list of keywords. The second phase uses Boolean operators AND/OR to select queries to search for and collect all relevant data. Table 4 gives the list of fundamental, Primary & Secondary Keywords. Table 5 shows the search queries used in this article. In Table 5, # indicates the number of the initial result.
Table 4. List of primary and secondary keywords used.
Table 5. Search queries.
As given in Table 6, the authors established a set of inclusion criteria for research paper selection and rejection exclusion criteria for selecting appropriate research studies for systematic review. In the screening procedure, three steps of inclusion criteria are established as follows:
Table 6. Summary of inclusion and exclusion criteria.
(i)Abstract-based screening: Disqualify irrelevant research papers based on knowledge and keywords in research abstracts. Abstracts of research papers that met at least 40% of the inclusion criteria were considered for the following steps.(ii)Full-text screening: The authors eliminated research papers that did not address or contribute to the search query in Table 5, i.e., abstracts that only represented minor aspects of the search query.(iii)Quality-analysis step: The remaining research papers were subjected to a quality assessment, and those that did not meet any of the following requirements were eliminated:(iv)C1: Findings and outcomes must include in research articles.(v)C2: The findings of research publications are supported by empirical evidence.(vi)C3: The research goals and findings must be well presented.(vii)C4: Appropriate and sufficient references must use in research papers.
The authors utilized the following steps to choose appropriate papers for this research: As represented in the PRISMA flow diagram, the measurements of identification, screening, eligibility, and inclusion. Figure 3 depicts a PRISMA (Preferred Reporting Items for Systematic Review and Meta-Analysis) flowchart diagram showing the identification and records selection process of studies for the systematic review [37]. In Figure 3, # is used to indicate the process of screening is followed. Scopus and Web of Science (WoS) are well-known and standard research databases for searching the query. Two hundred eighty-three research articles from Scopus and 188 from WoS are retrieved using a search query. A total of 471 records are further gone through the first screening process of duplicate records removal. One hundred eighty-seven duplicate records are removed based on doi and title. Later, 284 documents were undergone through a second screening process using inclusion and exclusion criteria of the title and abstract.

Figure 3. Flowchart identifies and selects studies for systematic review using the PRISMA approach [38].
Further, 98 documents still need to meet the inclusion criteria. Hence, 186 papers are forwarded to check for eligibility criteria. Based on inclusion and exclusion criteria for full text, the number of documents included for review is 95. Authors critically review these 95 research articles to find the research gaps in the existing literature and future directions in facing anti-spoofing.
The findings of the systematic analysis are summarized in this section. It presents the responses to the mentioned research questions based on the findings of this review procedure, which follows an examination and analysis of 93 papers. Section 3.1 discusses research question 1 (RQ1) about the distribution of publication trends; Section 3.2 discusses research question 2 (RQ2) about various attacks on face liveness detection systems. Section 3.3 gives the comparative analysis of standard datasets used in literature that address research question 3 (RQ3) taken up for study.
RQ1: What is the distribution of published papers related to face liveness detection techniques by year, publication, and publication type?
Research articles used for the study were analyzed as par publication trends by year, reports by publisher, and publication type. There is a total of 95 research articles used for analysis purposes. Figure 4 shows the distribution of research articles by (a) publication year, (b) publication type, and (c) publication house. Research articles used for the study were analyzed as par publication trends by year, publisher, and publication type. There is a total of 95 research articles used for analysis purposes. In 2020 & 2021, the maximum number of research articles got published. Authors have considered research articles published up to June 2022, five papers. A maximum of 64 papers are published in IEEE and followed by Springer, 12 in the count. The research articles for this study were published as conference papers, articles, and proceeding papers. The contribution on Conference papers is 51%, Article papers are 47% & proceeding papers are 2%. As per the analysis, this topic has significant strength in research.

Figure 4. Analysis of selected research articles by (a) Publication Year, (b) Publication type, and (c) Publishing house.
With the advancement in technology, facial recognition systems have increased so widely. Along with that, the challenges or threats to facing recognition systems also come into the picture. Intruders use various spoofing techniques to fool the facial recognition-based authentication systems, known as Face Spoofing attacks and are also commonly termed Face presentation attacks. The different types of spoofing techniques or attacks are discussed in this section. Face Spoofing attacks are classified as shown in Figure 5.
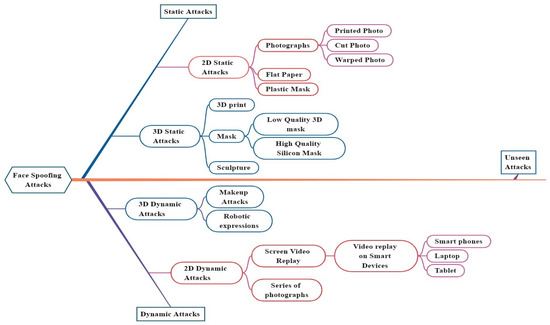
Figure 5. Categorization of Face Spoofing Attacks and Spoof Instruments.
The face spoofing attacks are broadly categorized as static attacks & dynamic attacks, whereas those are sub-classified by 2D or 3D static & dynamic attacks.
2D Static Spoofing attacks are when intruders employ pictures, flattened papers, and masks for authentication. Images taken on paper are kept in front of the face recognition system by intruders to get access to the systems. A paper should be of good quality and in the A3 or A4 size. As seen in Figure 6a, printed picture attacks are one type of printed photo attack. It is the most common type of attack as it is easy to perform due to the large availability of individual pictures on social media. Another approach to spoof images is to cut a printed photo on the eyes or lips region to add some liveliness to the photo kept in front of the camera; this is known as a cut photo attack, as shown in Figure 6b. As face recognition-based systems get prone to attacks, intruders also come with different attacks. Another method for creating spoof photographs is to hold a genuine user’s photo in front of the camera in a tilted position, either horizontally or vertically, to give the image depth. As demonstrated in Figure 6e, this method is known as a wrapped photo attack.

Figure 6. Sample Face spoofing attacks (a) Photo attack sample from OULU-NPU dataset [39] (b) Photo cut attack OULU-NPU attack [39] (c) Replay Attack Sample [40] (d) Flat Printed photo attack (e) Wrapped photo attack (f) 3D Mask generated using Face Construction using front-side faces (g) Sample 3D Latex mask from MLFP DB [41], (h) 3D model attack [42].
The matte paper and printed masks, plastic masks, are used as attacking instruments. 2D static attacks are quick and straightforward to execute in actual circumstances, necessitating sophisticated facial recognition algorithms.
Furthermore, a high-definition photo on a smartphone screen, a series of high-definition images, and a video of a genuine person on the screen of smart and portable devices shown in front of the camera of face authentication systems are other approaches to spoofing attacks. These attacks are 2D dynamic attacks. Video replay attacks are superior to 2D static photo attacks because they incorporate unique features such as eye movements, lip motions, and shifts of facial emotions to simulate liveness. Replay attacks are often harder to spot than photograph spoofs since they imitate the texture and contour of the face and its dynamics, such as eye movements, lips, and facial expressions.
Facial recognition systems vulnerable to 2D static picture attacks would perform significantly worse against 2D dynamic video attacks. Being robust against photo attacks can mean something other than being similarly strong against video attacks. As a result, appropriate measures should be designed and implemented for robust face recognition systems.
This type of attack provides a 3D mask of the person’s face. The attacker creates a three-dimensional reconstruction of the victim’s face and shows it to the camera/sensor. Mask attacks involve more significant expertise than 2D static and dynamic attacks and access to additional facts to generate an accurate mask of a legitimate user. 3D static attacks employ a 3D mask as an instrument of 2D images adhered to a flexible structure such as a shirt or plastic bag. Such attacks fool low-level 3D face recognition systems. Different Sculptures are also used as attacking instruments in 3D static attacks. Two or more photos of the actual user’s face, such as one frontal shot and one profile shot, can be used to create 3D models. The attacker may be able to extrapolate a 3D reconstruction of the real face using these images.
Another type of 3D attack is a makeup presentation (M- PA) attack. For impersonation, the attacker may use heavy makeup to mimic the facial look of a target subject [37]. It was discovered that high-quality makeup attacks that resemble the facial texture and form of an impersonated target subject might represent a severe threat to the security of face recognition systems. Silicon can make high-quality 3D masks; this is another approach to 3D static attacks. Figure 6f–h shows some sample 3D mask attacks. A more advanced method is taking a direct 3D capture of a real user’s face. This approach has more difficulty because 3D acquisition can only be done with specialized equipment and is impossible without the end’s involvement. 3D dynamic attacks include using sophisticated robotics to reproduce expressions and complete makeup as a tool for making 3D reconstructions of real faces. However, Due to the spoofs’ high realism, this attack may be more likely to succeed [39]. 3D masks present additional hurdles to the FR system; the Multi-Modal Dynamics Fusion Network (MM-DFN) technique is being investigated [42]. It gets more challenging to create effective countermeasures as the entire face structure is copied. 3D mask attacks are predicted to become increasingly common in future years as 3D acquisition sensors become more ubiquitous.
RQ 3: What are the different datasets available for different types of presentation attacks? Data is the foundation of any artificial intelligence model. Obtaining particular, unbiased data from the right source would help build a more accurate and dependable model. This section discusses the most widely used publicly accessible datasets for detecting face presentation attacks. Table 7 gives an overview of existing 2D & 3D face presentation attack datasets used in the literature. In this table # sign is used to indicate the number of samples or subjects.
Table 7. 2D & 3D attack Datasets that are publicly available and used in the study.
The various face liveness detection AI-based techniques discussed in the literature are categorized based on the ML approach [102,103,104,105] & Deep Learning Approach [106,107,108,109]. Studies reveal that artificial intelligence-based methods for detecting face-presentation attacks are frequent. The first Section 4.1, discusses Feature extraction and Machine Learning approaches, followed by Section 4.2 on deep learning in face liveness detection.
The numerous feature extraction methods and classifiers categorize face liveness detection strategies. Texture, depth, motion, image quality, and multi-fusion techniques were employed as features. In contrast, findings from selected literature use various machine learning classifiers such as Support vector machines (SVM), Random Forest, naïve Bayes, Decision trees, and J48 [110]. Figure 7 shows the overview of Face presentation attack detection using the ML approach.
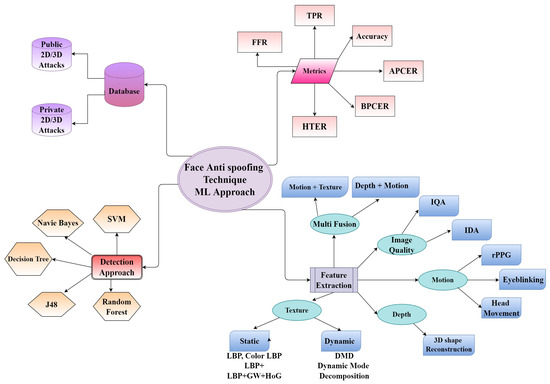
Figure 7. Face anti-spoofing techniques using a machine learning approach.
Texture features are one of the most well-explored strategies for identifying features in literature. Photos, replays, and 3D masks were detected with this tool. In general, static and dynamic aspects are separated—static features extract features from a single image, whereas dynamic features work on video frames. Static Feature extraction methods help detect static face presentation attacks such as printed photos, cut photos, wrapped photos, printed masks, etc. In contrast, Dynamic feature extraction methods address dynamic face presentation attacks such as video replay attacks, 3D Mask occlusion attacks, etc. For static texture feature extractions in the literature, various methods are used, such as Local Binary patterns (LBP) [40], DoG [111], Gabor wavelets, and HoG [112], whereas LBP is explored more in the literature. Each pixel is labeled by comparing its neighbors and concatenating it into a binary number using LBP texture coding. In addition to the coding strategy, other parameters include the number of neighbors and neighborhood radius. A histogram of the final calculated labels describes the texture, done for the whole image or selected image paths. The author [113] developed a color texture analysis-based face anti-spoofing solution. They created the final descriptor by connecting a single image channel LBP histogram. This method considers the three-color spaces RgB, YCbCr, and HSV to determine the most discriminating. Experiments demonstrate that the process based on color texture outperforms the grey surface in identifying diverse attacks. The same technique tailored for video attacks is used to investigate replay attack detection.
However, these approaches have the advantages of being simple to implement and requiring no user engagement. On the other hand, these approaches required feature vectors and performed poorly with low- resolution photos.
Motion cue-based algorithms use motion cues in video data to discriminate between genuine (live) faces and static photo assaults. Any dynamic physiological indication of life, such as eye blinking, lip movement, lip-reading [114], changes in facial expression, and pulse rhythm, is used as liveness cues. These approaches can identify static picture attacks but not video replay using motion/liveness signals or 3D mask attacks. According to [115] research, lip language recognition employs to identify changes in facial expressions, combined with voice recognition, to determine whether the user reads the randomly selected statements under specifications. Singh et al.’s blinking and lip movements were used to make real-time judgments. The HSV (hue, saturation, value) computes to determine whether the eyes and the mouth are open. They responded to phrase prompts generated at random by the algorithm and completed the required action to prove that it was a genuine person. Ng et al. [116] developed to guide users through making random facial expressions. By measuring the SIFT flow energy of several image frames, users may judge if the mandated facial expressions are complete and genuine faces.
The human-computer interaction-based technique can successfully mitigate inter-class discrepancies in algorithm performance through correctly designed interaction actions. Therefore, it has a high recognition rate and many other applications. Real-world business issues such as public safety, medical treatment, and finance use it frequently. On the other hand, a face anti-spoofing detection approach that relies on user-computer interaction requires much calculation and time to determine whether the user has completed action from a multi-frame image.
Most deceiving faces cannot replicate critical aspects such as a heartbeat, blood flow, and micro-movements of involuntary facial muscles. When using the life information-based technique, the differences in these vital qualities are primarily used to distinguish between living and fake faces.
The most extensively used approach for monitoring the micro intensity variations in the face that correlate to blood pulse is Remote PhotoPlethysmoGraphy (rPPG cue-based techniques). It can detect photo and 3D mask attacks because these PAIs lack the periodic intensity shifts characteristic of face skin.
However, ambient light and the item’s movements to be tested can readily influence the rPPG signal. Face anti-spoofing often requires cascading other traits and classifiers because the method is generally resilient.
There are different depths of information in various facial areas, such as the forehead, eyes, and nose tip. The photo- or video faces are two-dimensional, with the same depth of information at multiple locations. The depth information is used to detect fakes even though there are folded images. Depth information anti-spoofing methods typically need the usage of additional hardware. As a result of the difference in substance, the reflection properties of the fooled face differ from those of a living face’s skin, eyes, lips, and brows. When viewed in visible light, the deceived face appears to be similar to a real face, but it seems very different when viewed in infrared light. As near-infrared photos and videos show deceptive faces, this method is accurate, but well-made masks are less dissimilar from real faces. Steiner et al. [117] used short-wave infrared to distinguish between facial skin and mask attacks. A second use of the depth image captured by the depth camera is for anti-spoofing detection. A convolutional neural network and depth information from Kinect was used by Wang et al. [118] to distinguish between real and fake faces, as shown in Figure 8.

Figure 8. An illustration of CNN architecture used for face liveness detection.
There are several advantages to using depth information to identify face spoofing. There is a significant difference between a video face and a photo’s depth map; deprived of the excessive user interface, it has a good detection effect on photos and videos. A genuine expression, however, would have to invest in new technology, which would be pricey, and the latest hardware would also limit the number of users. In the depth map, the contours of the three-dimensional face can be seen, and there is a significant contrast between it and a photo face.
Presenting a deceptive human face necessitates plastic, silica gel, photo paper, electrical equipment, printing paper, and other media with qualities that differ from a real face’s facial features and skin materials. Variances in the reflection quality of materials, such as picture paper and mobile phone display screens, can induce. Both of which exhibit specular reflections but no living faces. The majority of picture quality after deception face secondary imaging differs from that of a living face, such as color distribution distortion and blurring of the prosthetic face image, even though the deception of the face manufacturing process is high. Image quality-based techniques use the variance among reflection and image distortion qualities to distinguish authentic and false faces.
The picture quality-based method has a low computational cost and a quick detection speed, making it ideal for online real-time detection. This approach, however, is open to attack when the image quality is excellent. A higher quality human face image and a false human face image should be used as inputs to obtain good enough image quality attributes. Table 8 gives the categorization of feature extraction for face liveness detection methods.
Table 8. Categorization of extraction methods for face liveness detection.
For spoof detection, face recognition systems use a variety of algorithms to assess static and dynamic information. Previously, used hand-crafted features to detect presentation threats in feature-based approaches. Hand-crafted feature methods used techniques such as Local Binary Patterns (LBP), Speeded-Up Robust Features (SURF), Histogram of Oriented Gradient descriptors (HOG), and Difference of Gaussian (DoG). Texture analysis extensively employs hand-crafted feature approaches. Textural characteristics vary de- pending on the spoofing medium and devices. As a result, generalization is low for these approaches. Deep learning approaches emerged, allowing for effective feature learning in various applications. Furthermore, deep learning algorithms outperformed hand-crafted methods in terms of detection. Hence, current developments show a significant move toward deep learning-based techniques for detecting face presentation attacks.
Deep learning-based algorithms have been effectively applied to various disciplines, including lip-reading from video, speech augmentation and recognition, medical imaging applications, security, anomaly, and so on. Convolutional neural networks have significantly advanced computer vision applications, particularly biometrics. Thanks to deep learning and its inherent feature learning capabilities, the anti-spoofing difficulty solve in a novel way. Existing deep neural network-based approaches have excellent intra-dataset performance. Figure 9 depicts the deep learning approaches for face liveness detection. In this section, a few deep learning approaches such as Convolutional Neural Networks (CNN), LSTM, Deep tree network (DTN), Autoencoders, Deep Neural Networks (DNN), Recurrent Neural Networks (RNN), Deep Belief Networks (DBN), and Generative Adversarial Networks (GAN) are discussed.

Figure 9. Deep learning approaches for Face liveness detection.
Deep learning-based techniques are used to learn texture properties automatically. Rather than directly creating the texture characteristics, researchers researching these methods focus on building a great neural network to learn optimal texture features [65]. In 2014, Yang et al. pioneered the road for deep learning in the arena of face anti-spoofing by introducing a Convolutional Neural Network (CNN) to extract features in face anti-spoofing.
Moreover, the features acquired from the CNN’s many layers were concatenated into a single element and input into an SVM for face PAD. But this strategy is prone to overfitting because the dimension of the fused feature is much larger than the number of training samples. Principal component analysis (PCA) and so-called part features are used to minimize the feature dimension. In 2016, Patel et al. proposed CaffeNet, a face PAD end-to-end system based on one-path AlexNet. In place of the original 1000-way softmax, a two-way softmax was used as a binary classifier. CNN was pre-trained on ImageNet, and WebFace to provide an appropriate initialization and fine-tuned using existing face PAD datasets. To train a deep CNN for face PAD, Li et al. recommended utilizing the VGG-Face algorithm. An extensive dataset is used to prepare the CNN, then fine-tuned using a (much smaller) face spoofing database [127].
Depth + Texture Feature Fusion: The image depth information is crucial for determining the face’s validity as the face in real life is three-dimensional, whereas the face attacked by photographs and screens is flat. The depth map differs from the real face, even if the face is deformed. A face depth map was initially used by Atoum et al. to distinguish between face spoofing. A two-channel CNN-based face anti-spoofing method was proposed in this study [96].
Spatial + Temporal Feature Fusion: Spatial characteristics of faces, such as texture and depth, are essential, but temporal factors are even more critical for anti-spoofing. Examining a human face from a time and space viewpoint can provide more helpful information and enhance classification performance.
Transfer learning is the most popular deep learning technique used in FPAD. A considerable amount of training data is often required to generate more distinct characteristics when using deep learning to detect face genuineness. However, there is insufficient data in the existing face anti-spoofing database, and most solutions use a neural network with only a few layers. A vast network classifier with good performance is challenging to train. Transfer learning helps avoid over-adapting to massive networks and saves a lot of computational resources when there is not enough data to train from the start [95].
Domain adaption (DA) and domain generalization (DG) used a transfer learning technique to improve generalization in FPAD. Domain adaptation is a strategy for transferring information from a source domain to a target domain. Adaptation is moving data from a source domain to a target domain using various methods.
In computer vision and machine learning, it is a frequent assumption that training and testing data come from the same distribution. However, many real-world scenarios (such as face recognition and spoof identification) require data from many distributions (facial appearance and pose, illumination conditions, camera devices, etc.). As a result, testing a pre-trained model with slightly different unseen data may have an over-fitting problem, resulting in a significant performance reduction. Domain adaptation is linked to transfer learning, which seeks to solve a learning issue in a target domain using training data from a source domain with a different distribution [98]. It has received much attention in recent computer vision tasks.
One of today’s most pressing concerns is improving face PAD algorithms’ generalization ability. Various strategies are explored, such as combining databases with a training model [128], NAS transfer learning approach [107,129] and one-class adaption [130]. Table 9 summarizes recent studies in face liveness detection.
Table 9. Few popular methodologies are used in Face Liveness Detection.
With the widespread use of deep learning in face anti-spoofing, many approaches have been presented. However, these methods are mainly confined to detecting known spoofing attempts, leaving unexpected spoofing assaults unnoticed. The following strategies were created to improve the generalization ability of detection systems under “invisible” attacks. Domain generalization is one of the strategies used by the biometric community to get generalizations in attack situations that are not yet known. There is a bias in existing face PAD approaches toward cues learned from training data. It is challenging to generalize against attacks that occur in various settings, devices, lighting situations, or materials. By considering both temporal and spatial information and limiting a cross-entropy loss and a generalization loss, the author [131] has aided in learning generalized feature representations. To increase the discriminability of the learned feature space, the author combined learning a generalized feature space with a dual-force triplet mining constraint [77]. Finding a compact and generalized feature space for fake faces is challenging due to the high distribution disparities among fake faces in different domains.
However, SSR-FCN is limited by the amount and quality of available training data, even though the suggested method is well-suited for generalizable face presentation attack detection. Cross-dataset generalization performance suffers when trained on a low-resolution dataset, such as Replay-Attack [129].
Face anti-spoofing prevents false faces from being recognized as actual users by face recognition systems. While sophisticated anti-spoofing solutions are developed, new types of spoof attacks are also being developed, posing a threat to all current systems. According to the author, detecting unknown spoof attacks is known as Zero-Shot Face Anti-spoofing (ZSFA). Liu. Y has presented a revolutionary Deep Tree Network (DTN) to combat the ZSFA. In an unsupervised manner, the tree is learned to segment the fake samples into semantic sub-groups. When a data sample arrives, whether from a known or unknown attack, DTN sends it to the closest spoof cluster and makes a binary judgment.
An anomaly detection approach was used to detect unseen attacks in recent research. The classification of one class preceded the discovery of anomalies. The types of attacks in practical applications are likely unknown, potentially occupying a large portion of the feature domain. As a result, one of the most significant potential issues in current anti-spoofing approaches is a failure to generalize on undiscovered sorts of attacks. First, the authors create novel assessment techniques for existing publicly available databases to highlight the generalization concerns of two-class anti-spoofing systems. Second, to combine the data collection efforts of many institutions, the author has created a problematic aggregated database that combines three publicly available datasets: Replay-Attack, Replay-Mobile, and MSU MFSD, and reports the result.
A unique approach is presented [140] that reformulates the Generalized Presentation Attack Detection (GPAD) problem from the standpoint of anomaly detection. A deep metric learning model was provided. A triplet focal loss is a regularization for a novel loss called ‘metric-SoftMax.’ It guides the learning process towards more discriminating feature representations in an embedding space. Finally, the benefits of deep anomaly detection architecture are proven by introducing a few-shot posterior probability calculation that does not require any classifier to be trained on the learned features. Table 10 summarizes the anomaly detection approaches in FLD.
Table 10. Anomaly detection in FLD.
The performance of face liveness Detection (FLD) systems was evaluated using ISO/IEC DIS 30107-3:2017. The authors reported the evaluation measures used to test various scenarios in a face-liveness detection system. Half Total Error Rate (HTER) is the most often utilized measure in anti-spoofing settings.
Face Liveness Detection is frequently thought of as a binary classification issue. The performance is assessed using a variety of performance-related measures. Because these binary classification methods have two input classes, they are sometimes referred to as positive and negative. The types of errors they make and their approach to measuring them are used to evaluate their performance. Binary classification techniques make use of False positives and False negatives. False Positive Rate (FPR) and False Negative Rate (FNR) are two often documented error rates (FNR). They calculate the average of FRR (ratio of incorrectly rejected genuine score) and FAR yields HTER (ratio of wrongly accepted zero-effort impostor) [142]. Attack Presentation Classification Error Rate (APCER), Average Classification Error Rate (ACER), and Bonafide Presentation Classification Error Rate are the three variables (BPCER) [143]. While evaluating Face presentation attacks, the classification of attacks, the real face, intra-dataset, and cross-dataset performance are considered [145,146]. BPCER and APCER are two different methods for calculating the rates of correct and false classification errors. ACER measures performance inside a dataset, while HTER measures performance across datasets. The Receiver Operating Characteristic (ROC) curve and the Area Under the Curve (AUC) are also widely employed to evaluate the performance of face liveness detection methods in addition to the HTER and ACER scalar values. Equations (1)–(6) show the formula for calculating measures.
HTER=FAR+FRR2HTER=FAR+FRR2
(1)
FAR=FPFake samplesFAR=FPFake samples