0xPARC
by gubsheep
A series on why new advances in cryptography may be important for digital identity primitives. The first post covers the “Why”; this post covers the “How.”
In our last post, we discussed why new cryptographic tools, such as zkSNARKs, will be crucial for constructing the next generation of digital identity infrastructure. In this post, we’ll dive into the weeds—what technical work needs to happen to build proof-of-concept ZK-based identity systems?
The ZK Identity “megaproject” is much larger than any one organization. Setting standards, building infrastructure, and iterating on identity primitives and application design questions will happen gradually, and require input from a variety of different stakeholders and areas of expertise. Given that ZK identity mechanisms have the potential to impact many people and also to rely heavily on public goods—open-source infra, tooling, standards, coordination—it is important that the effort arises bottom-up from an organic and community-driven “ecosystem,” rather than top-down from a single company; and that special attention is paid to sustainable development and incentive design.
It is also increasingly unlikely that an isolated company will succeed in such a dynamic ecosystem, as technology developed independently at all levels of the stack is changing rapidly. Instead, we’ll need to foster and coordinate an ecosystem of modular, fast-moving, and semi-independent teams sharing a common overall vision.
The 0xPARC ZK-identity working group hopes to contribute to the collective ZKID effort where we can, and we invite others who are actively thinking about this problem to join us and compare notes.
Building Blocks for ZK Identity
ZK Identity tools must enable participants in digital systems to make claims about identity and reputation. Concretely, these claims boil down to mathematical statements about the execution of cryptographic operations like signature verification, key generation, hashing, and encryption in zero-knowledge. We can combine these “building blocks” together to build ZKPs for more complex claims: for a toy example, see our post on ZK Group Signatures.
Some operations and cryptographic schemes can be implemented more efficiently in zkSNARKs than others. In the long term, SNARK-friendly cryptographic standards may be adopted by new identity providers that don’t yet exist today—for example, blockchains with public/private key signature schemes based on SNARK-friendly cryptography (or more expressive systems like account abstraction). But in order to prove concept and to be useful in the near term, our tools need to integrate cleanly with existing cryptographic identity systems—for example, Ethereum’s present ECDSA signature scheme, or more recent cryptographic standards coalescing around pairing-friendly elliptic curves in other contexts.
We believe that building a usable toolstack for ZK Identity applications will require significant progress on four fronts: ZK application design patterns, implementation of ZK circuits for cryptographic primitives, circuit security tools, and developer tools and infrastructure. We summarize each area below.
ZK Apps and Design Patterns
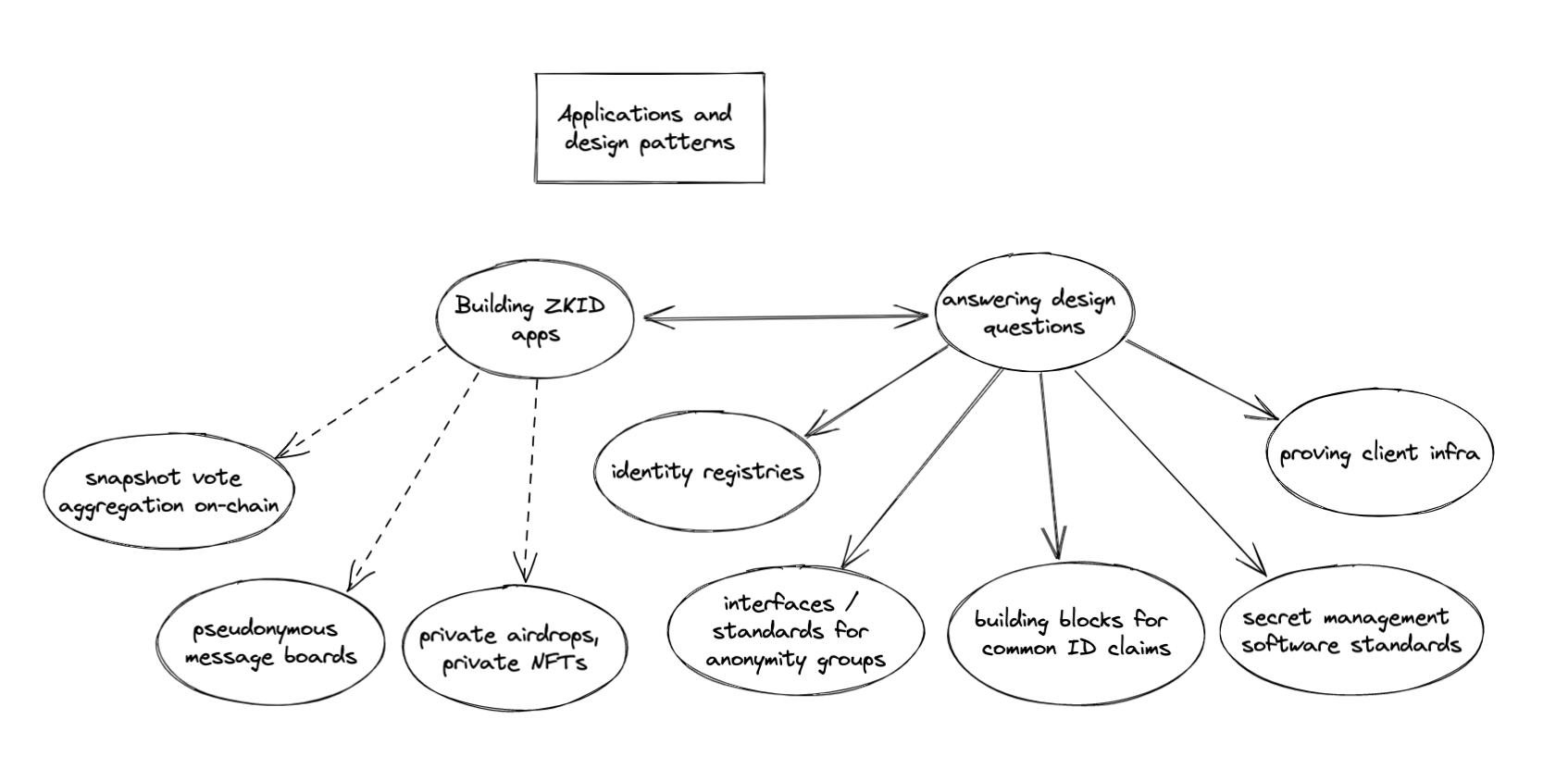
First off, the output of our work should be touching end users and enabling impactful production applications. In parallel with developing ZK tools and building blocks, we’ll have to figure out the best way to use and compose them. Here are a few open questions:
- What is the correct abstraction for identity? Is it an Ethereum address, a collection of Ethereum addresses, a multisig, a smart contract wallet, an ENS name, a keypair in a different cryptographic scheme, a secret biometric, a set of attestations, a higher-level construct, or something else entirely?
- What are common identity claims that people care about making? All of the above work gives us a language for making credible claims about identity; now, we have to learn how to actually speak in this language. For example, is it useful for claims to directly reference and operate on hash data stored on-chain, or is it easier if most claims are simply proofs of valid attestations by semi-trusted third-parties? Is it practical to make claims referencing historical Ethereum state in ZK proofs—and if so, what kinds of historical claims should a proving tool make easily accessible?
- What tools and standards should be expected from future ZK wallets and identity providers? For example, Metamask or hardware wallets currently support digital signing with a private key, and it is generally recommended that private keys should not be directly manipulated by users. However, ECDSA signature verification is much more expensive to perform in a SNARK than public key generation—meaning that users who wish to make ZK proofs about their ETH address will have to choose between much slower proving times (via proof of valid signed attestation) and lesser security (by copying their plaintext private key out of the wallet enclave and into ZK proof generation programs). This problem can be partially solved if wallet software eventually offers native support for ZK proof generation, which we’re currently experimenting on with the Metamask Snaps team.
- What interfaces will ZK-identity-enabled apps need to conform to? Applications both on- and off-chain will need to be designed with ZK identity systems in mind. For example, NFT-gated communities that wish to use ZK identity systems may want to also store a cryptographic accumulator of token and token owner data in the NFT smart contract, so that it is easier for users to generate claims about membership in the community. Standards for groups that we wish to make membership proofs for will need to be developed.
- Who (or what devices and environments) can generate ZK proofs? The space of viable applications looks very different depending on whether certain ZK proofs can be generated in hardware wallets, on mobile devices, in browsers, on consumer desktop computers, or only on dedicated proving servers.
The best way to answer these questions is just to start building! We hope that a robust developer community may start to form in the next few years, building applications with a variety of different approaches.
Several ZK-Identity apps can in fact be built today with the existing state of infrastructure. This is high-leverage work—beyond delivering useful applications, these projects will also inform development on tools and infrastructure. Here are some candidates for initial production applications of ZK Identity:
- Private airdrops. A common strategy for many DeFi apps is to publish a Merkle root of user addresses on-chain, and to allow users to claim airdrops by calling a function with an address published in the tree. Stealthdrop is one project from ETHUni and 0xPARC communities that adds a privacy layer to this by allowing users to claim an airdrop from any address by simply proving that they possess an attestation from some private key corresponding to an ETH address in the tree (with nullifier checks to prevent duplicate claims).
- On-chain Snapshot vote aggregation. Today, many “DAOs” use entirely off-chain voting mechanisms, where users sign votes and send these signatures to a central service provider (i.e. Snapshot) for tallying. This presents two problems: first, votes can be censored by the central authority, and past voting data can become lost or unavailable/unauditable. Second, votes are conducted publicly, leaving voting systems vulnerable to collusion. We can use ZK constructions for signature verification to “roll up” voting results into a single ZK proof of voter signatures that can be trustlessly generated and submitted on-chain. Intermediate constructions which partially distribute power from the central authority (i.e. to a wider network of attesters who post Merkle roots of tokenholder snapshots) in exchange for scalability are also possible.
- Anonymous but credible attestations. These identity tools can be used for proving membership in a group without revealing your exact identity—for example, proving ownership of a Dark Forest planet and joining an NFT-gated community without revealing your identity; making a post as an anonymous but popular Twitter user, proving that you have at least 1m+ Twitter followers without revealing your account; or proving that you’re a member of a legislature and anonymously signaling consensus in an upcoming vote. Some of these applications are discussed more in our ZK Group Signatures post.
ZK Circuits for Cryptographic Identity Primitive
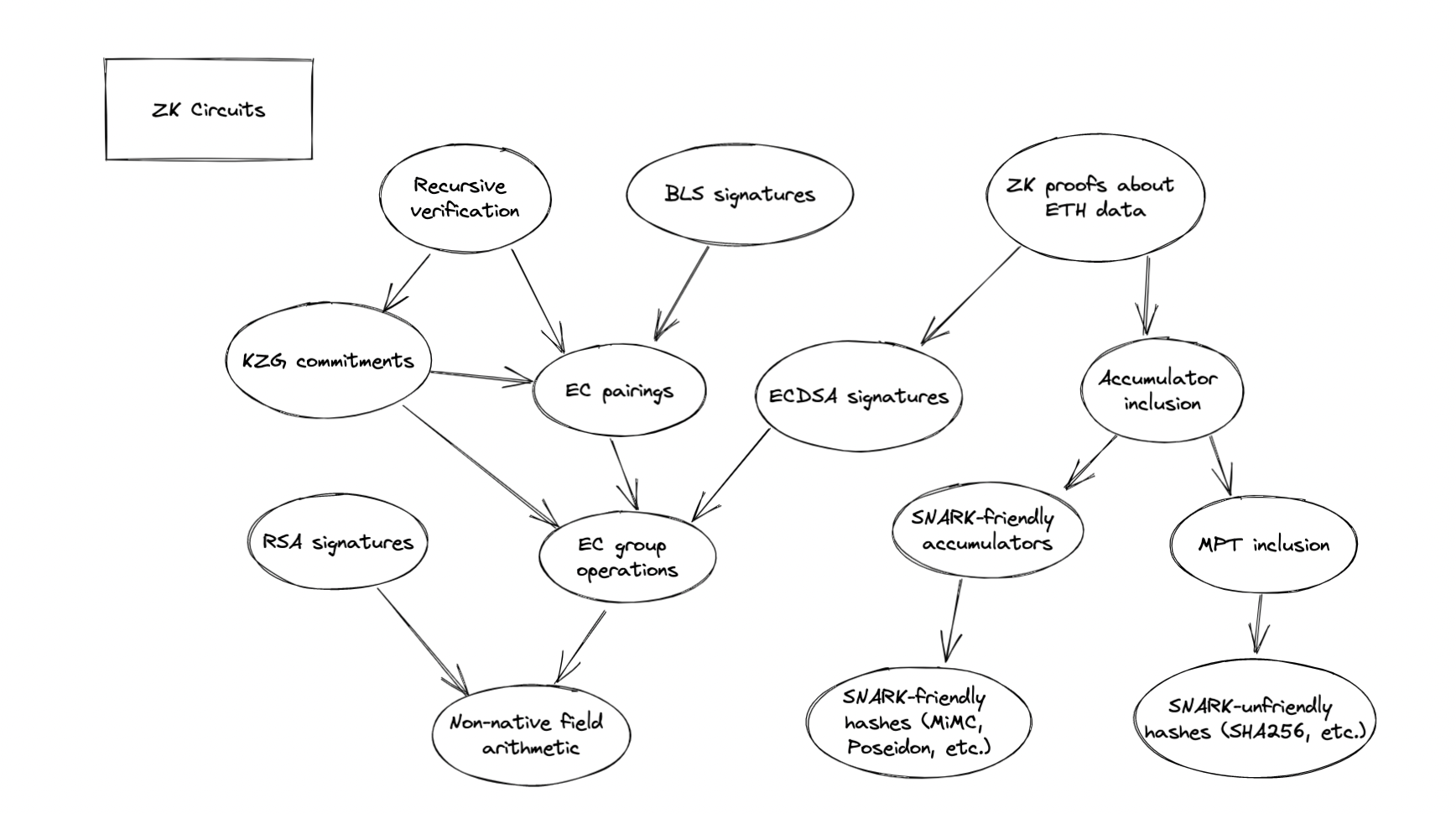
Stepping one level deeper in the stack, we need efficient, audited implementations of ZK circuits for core cryptographic primitives and the mathematical operations underlying them. Here is a sample of some key operations, in a very rough dependency ordering.
- Non-native field arithmetic: zkSNARK arithmetic takes place in a prime field—for example, all signals in the defaults for snarkjs are taken modulo the 254-bit BabyJubJub prime. However, cryptographic operations require us to perform operations on potentially much larger numbers—for example, secp256k1 operations require us to take the product of two 256-bit numbers modulo a third 256-bit number. The most expensive operations involved in these circuits are range checks, and one strategy for constraint optimization is to be more careful about determining when precisely we need to perform range checks.
- SNARK-friendly hash functions: Hash functions are useful in applications where users must make cryptographic commitments. In schemes where the hash function does not need to integrate with an existing standard, we can choose to design and implement hash functions that are specifically designed to be efficient in SNARK proofs. Two such functions include MiMC and Poseidon.
- SNARK-unfriendly but standardized hash functions: In many applications, we must use SNARK-unfriendly hash functions (like SHA256 or keccak) for the sake of compatibility with existing systems. For example, to prove knowledge of the private key corresponding to an ETH address, we need a ZK circuit implementation for keccak. There is lots of work to be done implementing, optimizing, and auditing these hash functions.
- Elliptic curve point addition: Elliptic curve cryptography is built on elliptic curve groups; therefore, we must build ZK implementations for the elliptic curve group law (point addition). These operations are expensive and this is one performance bottleneck for ZK identity systems; clever usage of PLONK and better implementations of BigNum arithmetic may help improve performance.
- ECDSA key generation and signature verification: ZK circuit implementations for ECDSA key generation and signature verification would allow us to build a language of identity claims that is compatible with existing ECDSA-based identity systems, such as Ethereum. Building these primitives requires us to combine implementations of EC point addition and hash functions in efficient ways.
- Elliptic curve pairing: Pairing-friendly elliptic curves give us access to bilinear maps, enabling polynomial commitments, BLS aggregate signature verification, recursive SNARK verification, Verkle Trees, and more. Efficient implementations of ZK circuits for elliptic curve pairings will unlock a huge variety of new cryptographic operations.
- Cryptographic accumulator inclusion checks: Verkle tree inclusion proofs are verifiable in SNARKs, once we have ZK circuits for polynomial commitment verification. Merkle tree inclusion proofs are verifiable today, and are practical for trees built with SNARK-friendly hash functions. MPT inclusion proofs enable us to verify light client proofs in a SNARK. In all of these cases, accumulator inclusion proof verification allows SNARKs to access data that is rolled up into a succinct commitment (”root”) of global system state—if you provide the data you’re accessing, the system state root, and a proof of inclusion as input to the SNARK, then the verifier only needs to verify your succinct proof and check that the root is correct, rather than the full system state.
- Recursive SNARK verification: Recursive SNARKs are made possible by implementation of elliptic curve pairings and/or polynomial commitment verification inside of zkSNARKs. This unlocks a new dimension of programmability and complexity in identity claims.
Circuits for all of these might first be written for R1CS (allowing for groth16 setup and proving in the near term), and in the near future optimized further for PLONK-based proving systems.
Developer Tools and Infrastructure
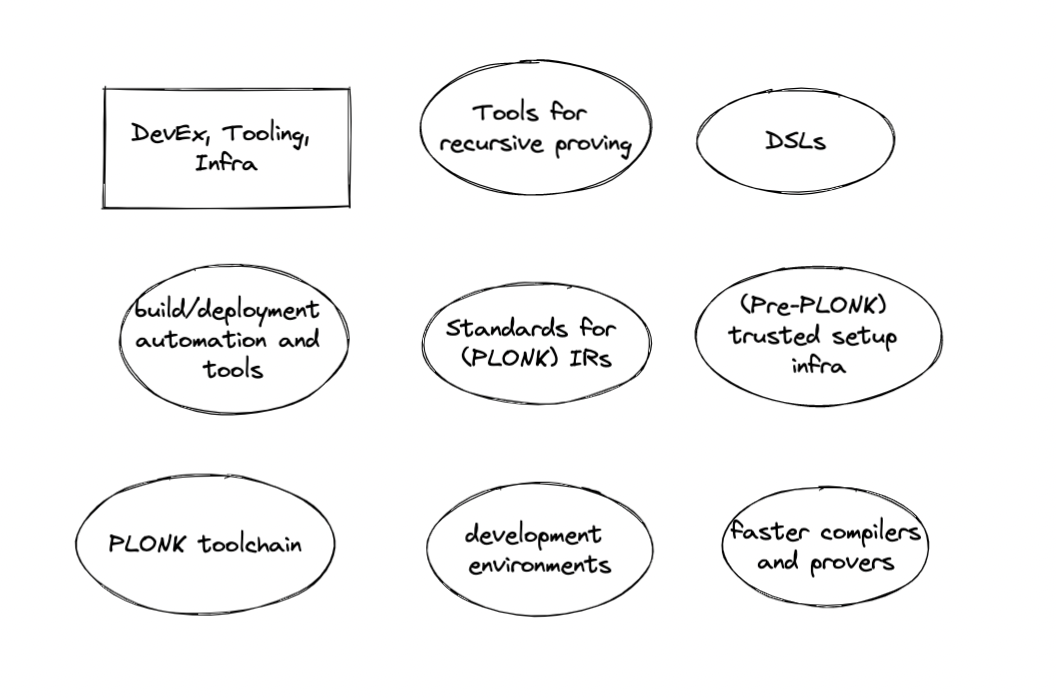
Developer tooling for ZK circuit engineering is an important topic. Currently, ZK developers require a relatively high level of mathematical background and technical sophistication, they must write in relatively low-level development environments, and they rely on manual effort or ad-hoc scripts to manage files and carry circuits through the development pipeline from design to production. Furthermore, the developer tooling work that has been done is scattered and fragmented among multiple R&D teams, rollup companies, and more.
Of special note here is the importance of a robust toolstack for PLONK specifically. PLONK removes the need for per-circuit trusted setup, significantly speeds up compilation and proof generation for certain circuits thanks to custom constraints, and paves the way for recursive SNARK verification. However, tooling for PLONK is currently at a much earlier stage of development than Groth16 tooling, as provers are much less optimized and support for advanced protocol features is not yet implemented in certain systems. Furthermore, much work remains to be done on standards for IRs and the design of a language for custom constraints. Groups like AZTEC, Electric Coin Co, iden3, ZK-Garage, and more are hard at work building these tools.
Beyond PLONK toolchains, here are a few active areas of work in ZK developer tooling.
- Higher-level DSLs. Current languages for writing SNARKs are very low level, and require developers to manually write constraints. We are interested in production-grade higher-level DSLs that are easier to develop in (one proof-of-concept from a 0xPARC community member) or which may even perform constraint optimizations intelligently. Additional nice-to-haves include user-defined data types/annotations, and better witness generation systems. Further down the line, DSLs that enable automation of testing, verification, or static analysis of circuits may increase our confidence in the code that we write.
- Smarter development environments. Writing, analyzing, and testing circuits is a difficult process. Syntax highlighting, detection of compile-time errors during development, IntelliSense-like tools using a combination of AST/witness analysis, annotations (i.e. marking circuit templates as “safe” or “unsafe,” flagging unconstrained signals), and shell/REPL environments may improve iteration speed rapidly. ZK Learning Group participants were sped up massively by Kevin Kwok’s ZKREPL project, which incorporates a number of the above-described features.
- Build, testing, and deployment tools; automation and pipeline management. ZK developers must currently manage ptau files, key files, build configurations, build files, and release distribution processes manually. The snarkjs tutorial currently lists 26 steps that a developer must perform to create and verify a zkSNARK, involving manual operations on over 20 files. There aren’t widely-accepted best practices for how to publish protocol parameters in a way that is accessible and auditable. Different versions of circuits must be maintained manually for different environments (i.e. turning off some constraints during testing). Tools like ProjectSophon’s hardhat-circom and Weijie Koh’s circom-helper are great first steps that help to simplify workflows drastically, but much work remains to be done.
- Common standards for intermediate representations. Different teams use different languages and tools to write ZK circuits: circom, arkworks, libsnark, and many more. Circuits written with different toolchains should ideally compile to a common IR so that generating proofs, verifying proofs, auditing protocol setups, and other common tasks can be toolchain-agnostic. For Groth16, an IR depends on a standard set of of agreed-upon cryptographic parameters and R1CS representation. For PLONK, the problem is a bit more complex, as library developers will need to figure out how to represent custom constraints and more. As an example of work in this problem space, development of a Dark Forest 3rd-party client motivated Kobi Gurkan and gakonst to write ark-circom, bridging the arkworks and circom ecosystems.
- Easier-to-use and more efficient compilers and provers. Slow key compilation and proving slows development and testing. Optimizing compilation and proving, and making libraries for these processes easy to run out-of-the-box (i.e. setting up a remote prover on a big server should be easy!) will save developers time. ZPrize is one industry initiative that aims to accelerate this work and more.
- (Pre-PLONK) Shared trusted setup infrastructure. Production-grade zkSNARK apps are difficult to launch right now because of the difficulty in coordinating trusted setup. ZCash, AZTEC Protocol, Tornado, and Semaphore all had to write customized trusted setup infrastructure. There have been some attempts to build out more reusable trusted setup tooling, but running these ceremonies is still extremely labor-intensive. Note that this will likely not be a problem in the longer term however as we move to protocols that don’t require per-circuit trusted setup.
- (Post-PLONK) Tools for working with SNARK recursion. SNARKs that support recursive verification enable us to build “programmable” SNARKs, where SNARK code could be modified “on-the-fly” by plugging in verifying keys to other SNARK submodules. Furthermore, recursive SNARKs also allow developers to parallelize proof generation. Supporting this functionality in practice is a hard problem that will likely be worked on for the next several years...
Auditing and Verification
The above-listed circuits are complex and extremely hard to verify manually. Clever constraint optimizations actually compound the problem—highly-optimized circuits are hard to reason about, and its easy to miss a constraint during implementation if you’re doing something tricky. Furthermore, it can be impossible to tell if a bug in a ZK circuit has been exploited in the wild, due to the nature of ZK applications.
It’s fairly easy to write tests that give you confidence of completeness: demonstrating that you can generate witnesses and valid proofs for witnesses properly from inputs. Gaining confidence in soundness is harder. To do this, you’d have to verify that there is a unique witness that satisfies the constraint system of a SNARK for a given input—that a malicious prover can’t substitute in a faulty witness that generates a valid proof due to a missing constraint. Even harder than this is proving equivalence of a circuit to a specification, i.e. formal verification.
Currently, the approach taken by most teams using ZK circuits in production is to commission manual, human audits, though the quality of these audits is inconsistent and the total number of people capable of performing audits is very small. We may be reasonably certain that applications like Tornado.Cash, whose circuits total only about 100 lines of circom code, are probably secure. However, our proof-of-concept groth16 ECDSA implementation relies on thousands of lines of circom code, with circuit sizes in the hundreds of thousands or millions of constraints. More complex primitives will be even harder to verify, and PLONK custom constraints will add additional complexity.
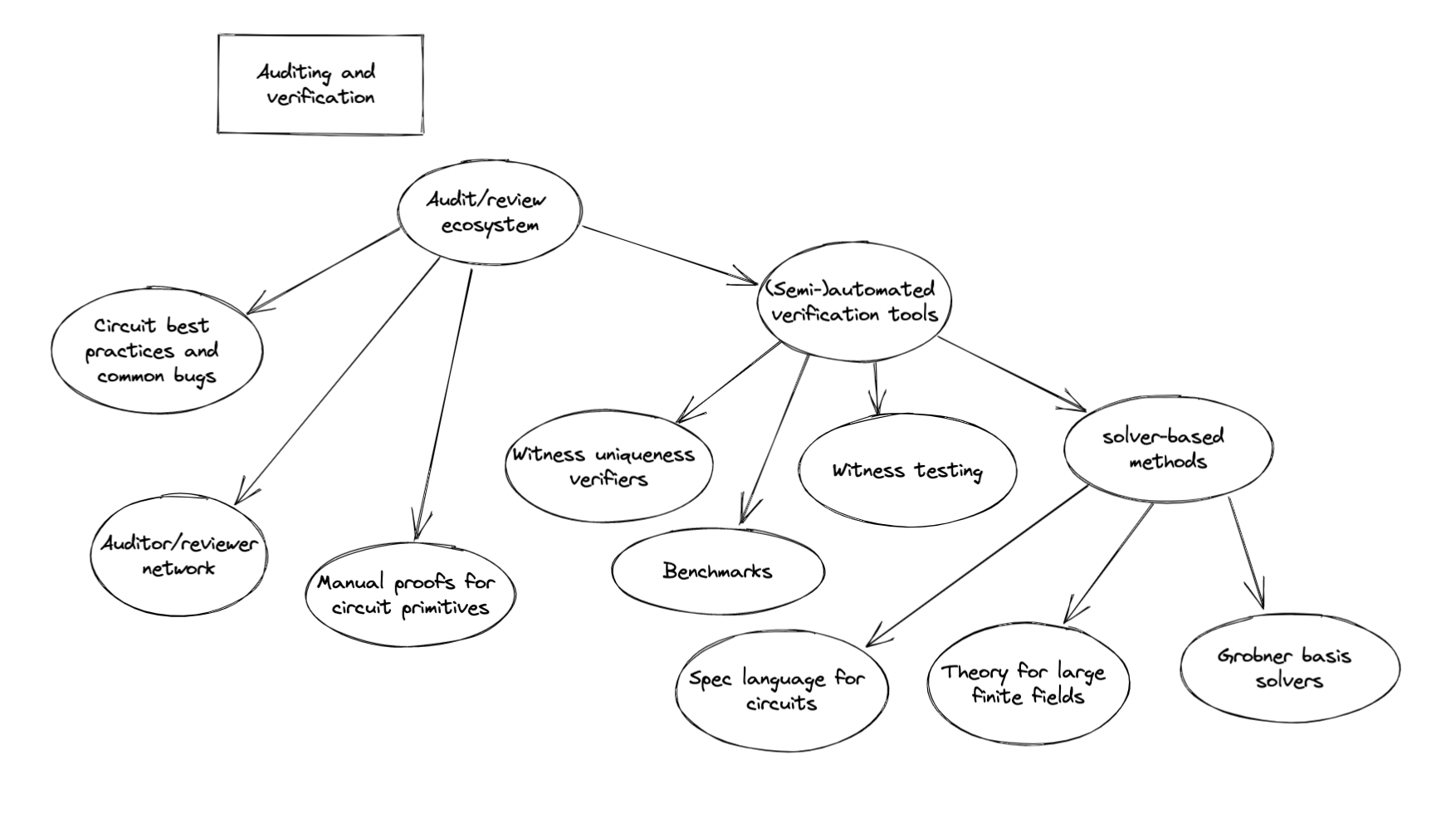
We suggest a handful of approaches for the ZK application security space. In the future, we’ll publish a blog post with a deeper overview of current approaches in this domain that we are aware of.
- Building a community of reviewers. Teams often have difficulty finding specialists with expertise with ZK application development to review their circuits and code. We can encourage existing ZK-focused teams, such as engineers at rollup companies as well as application developers, to “trade” reviews, and we can also collectively begin to train auditors.
- Establishing best practices for circuit engineering and review. As the ecosystem matures, we will want to develop best practices for building, annotating, documenting, and reviewing ZK circuits. This can be done to varying degrees—specifications in natural language or formal specs are both helpful in making circuits more legible. Enumerating common bugs and mistakes (and building some rudimentary tools for catching these) may also help both engineers and auditors.
- Manual proofs of correctness for circuit primitives. For important primitives, such as hash function or ECDSA circuits, it may be possible to manually write proofs of correctness for such primitives that can be checked with a proof checker. Other circuit builders would then be able to use these primitives with greater confidence in their correctness.
- Automated witness uniqueness verification. Ecne is the first automated R1CS witness uniqueness verifier. This project enables us to verify whether or not a ZK circuit may have any missing constraints, which is a major step forwards in building confidence in our ZK systems. We hope to support and encourage more work in similar directions.
- Solver-based methods for formal verification. Some teams are exploring automated methods for proving the equivalence of a ZK circuit with a formal specification. Efforts in this area will also require us to develop a common set of benchmarks, as well as a language for specifying ZK circuits (partially or completely).
一系列关于为什么密码学的新进展可能对数字身份原语很重要的系列。第一篇文章涵盖了“为什么”;这篇文章涵盖了“如何”。
在上一篇文章中,我们讨论了为什么新的加密工具(例如 zkSNARKs)对于构建下一代数字身份基础设施至关重要。在这篇文章中,我们将深入探讨——构建基于概念验证 ZK 的身份系统需要进行哪些技术工作?
ZK 身份的“大型项目”比任何一个组织都要大得多。设置标准、构建基础设施以及迭代身份原语和应用程序设计问题将逐渐发生,并且需要来自各种不同利益相关者和专业领域的投入。鉴于 ZK 身份机制有可能影响许多人,并且严重依赖公共产品——开源基础设施、工具、标准、协调——重要的是,这种努力从一个有机的和社区驱动的自下而上产生“生态系统”,而不是从一家公司自上而下;并且特别关注可持续发展和激励设计。
一家孤立的公司也越来越不可能在这样一个动态的生态系统中取得成功,因为在堆栈的各个级别独立开发的技术正在迅速变化。相反,我们需要培养和协调一个由模块化、快速移动和半独立的团队组成的生态系统,共享一个共同的整体愿景。
0xPARC ZK-identity 工作组希望尽我们所能为 ZKID 的集体努力做出贡献,我们邀请其他积极思考这个问题的人加入我们并进行比较。
ZK 身份的构建块
ZK 身份工具必须使数字系统中的参与者能够对身份和声誉进行声明。具体来说,这些主张归结为关于在零知识中执行签名验证、密钥生成、散列和加密等加密操作的数学陈述。我们可以将这些“构建块”组合在一起,为更复杂的声明构建 ZKP:有关玩具示例,请参阅我们关于ZK 组签名的帖子。
在 zkSNARKs 中,一些操作和加密方案可以比其他的更有效地实现。从长远来看,对 SNARK 友好的密码标准可能会被当今尚不存在的新身份提供者采用——例如,具有基于 SNARK 友好密码学的公钥/私钥签名方案的区块链(或更具表现力的系统,如帐户抽象) )。但是为了证明概念并在短期内有用,我们的工具需要与现有的加密身份系统干净地集成——例如,以太坊目前的 ECDSA**签名方案,或者在其他领域中围绕配对友好**椭圆曲线合并的更新的加密标准上下文。
我们认为,为 ZK 身份应用程序构建一个可用的工具堆栈将需要在四个方面取得重大进展:ZK 应用程序设计模式、加密原语的 ZK 电路实现、电路安全工具以及开发人员工具和基础设施。我们在下面总结了每个领域。
ZK 应用程序和设计模式
首先,我们工作的输出应该是触及最终用户并启用有影响力的生产应用程序。在开发 ZK 工具和构建块的同时,我们必须找出使用和组合它们的最佳方式。以下是一些未解决的问题:
-
身份的正确抽象是什么?更高级别的构造
它是以太坊地址、以太坊地址的集合、多重签名、智能合约钱包、ENS 名称、不同加密方案中的密钥对、秘密生物特征、一组证明、
,还是其他完全?
-
人们关心的共同身份声明是什么?
上述所有工作为我们提供了一种语言,可以对身份做出可信的主张;现在,我们必须学习如何用这种语言实际说话。例如,声明直接引用和操作存储在链上的哈希数据是否有用,或者如果大多数声明只是半可信第三方的有效证明证明,是否更容易?在 ZK 证明中引用历史以太坊状态的声明是否可行?如果是,证明工具应该让哪些类型的历史声明易于访问?
-
未来 ZK 钱包和身份提供者应该期待哪些工具和标准?Metamask Snaps
例如,Metamask 或硬件钱包目前支持使用私钥进行数字签名,一般建议不要让用户直接操作私钥。然而,在 SNARK 中执行 ECDSA 签名验证比生成公钥要昂贵得多——这意味着希望对其 ETH 地址进行 ZK 证明的用户将不得不在更慢的证明时间(通过有效签名证明的证明)和安全性较低(通过将他们的明文私钥从钱包飞地复制到 ZK 证明生成程序中)。如果钱包软件最终为 ZK 证明生成提供本机支持,这个问题可以部分解决,我们目前正在与
团队进行试验。
-
启用 ZK 身份的应用程序需要遵循哪些接口?
链上和链下的应用程序都需要在设计时考虑 ZK 身份系统。例如,希望使用 ZK 身份系统的 NFT 门控社区可能还希望在 NFT 智能合约中存储代币和代币所有者数据的加密累加器,以便用户更容易生成关于社区成员资格的声明。需要为我们希望为其制作成员资格证明的团体制定标准。
-
谁(或什么设备和环境)可以生成零知识证明?
可行应用程序的空间看起来非常不同,具体取决于某些 ZK 证明是否可以在硬件钱包、移动设备、浏览器、消费台式计算机或仅在专用证明服务器上生成。
回答这些问题的最好方法就是开始构建!我们希望在未来几年内可以开始形成一个强大的开发者社区,使用各种不同的方法构建应用程序。
事实上,现在可以使用现有的基础设施状态构建几个 ZK-Identity 应用程序。这是一项高杠杆工作——除了提供有用的应用程序之外,这些项目还将为工具和基础设施的开发提供信息。以下是 ZK Identity 初始生产应用的一些候选对象:
-
私人空投Stealthdrop
。许多 DeFi 应用程序的一个常见策略是在链上发布用户地址的 Merkle 根,并允许用户通过调用树中发布的地址的函数来领取空投。
是来自 ETHUni 和 0xPARC 社区的一个项目,它为此添加了一个隐私层,它允许用户通过简单地证明他们拥有与树中的 ETH 地址相对应的某个私钥的证明来从任何地址索取空投(带有无效检查以防止重复索赔)。
-
链上快照投票聚合串通
。如今,许多“DAO”使用完全脱链的投票机制,用户在其中签署投票并将这些签名发送给中央服务提供商(即快照)进行计票。这带来了两个问题:首先,投票可能会受到中央机构的审查,过去的投票数据可能会丢失或不可用/不可审计。其次,投票是公开进行的,使投票系统容易被
. 我们可以使用 ZK 结构进行签名验证,将投票结果“汇总”成单个 ZK 投票者签名证明,可以在链上进行不信任的生成和提交。将部分权力从中央机构分配(即分配给更广泛的证明者网络,他们发布代币持有者快照的 Merkle 根)以换取可扩展性的中间结构也是可能的。
-
匿名但可信的证明。帖子
这些身份工具可用于在不透露您的确切身份的情况下证明某个群组的成员身份——例如,在不透露您的身份的情况下证明黑暗森林星球的所有权和加入 NFT 门控社区;以匿名但受欢迎的 Twitter 用户的身份发帖,证明您拥有至少 100 万以上的 Twitter 关注者,而无需透露您的帐户;或证明您是立法机构的成员,并在即将举行的投票中匿名表示达成共识。其中一些应用程序在我们的 ZK 组签名
中进行了更多讨论。
加密身份原语的 ZK 电路
在堆栈中更深一层,我们需要针对核心密码原语及其背后的数学运算对 ZK 电路进行有效、经过审计的实现。这是一些关键操作的示例,以非常粗略的依赖顺序排列。
-
非本地字段算术BabyJubJub 素
:zkSNARK 算术发生在素数字段中——例如,snarkjs 的默认值中的所有信号都以 254 位
数为模。但是,加密操作要求我们对可能更大的数字执行操作——例如,secp256k1 操作要求我们将两个 256 位数字的乘积取模第三个 256 位数字。这些电路中涉及的最昂贵的操作是范围检查,而约束优化的一种策略是更加小心地确定我们何时需要执行范围检查。
-
SNARK 友好的散列函数MiMCPoseidon
:散列函数在用户必须做出加密承诺的应用程序中很有用。在哈希函数不需要与现有标准集成的方案中,我们可以选择设计和实现专门设计用于在 SNARK 证明中高效的哈希函数。两个这样的功能包括
和
。
-
SNARK 不友好但标准化的哈希函数keccak
-
椭圆曲线点加法代价高昂
-
ECDSA 密钥生成和签名验证组合
-
椭圆曲线配对
-
密码累加器包含检查
-
递归 SNARK 验证
所有这些的电路可能首先为 R1CS 编写(允许在短期内进行 groth16 设置和证明),并在不久的将来进一步优化基于 PLONK 的证明系统。
开发人员工具和基础设施
ZK 电路工程的开发人员工具是一个重要主题。目前,ZK 开发人员需要较高的数学背景和技术水平,他们必须在较低级别的开发环境中编写,并且从设计开始,他们依靠人工或 ad-hoc 脚本来管理文件和承载电路。到生产。此外,已经完成的开发人员工具工作分散在多个研发团队、汇总公司等之间。
这里需要特别注意的是,强大的工具栈对于 PLONK 的重要性。PLONK 消除了对每个电路可信设置的需求,由于自定义约束,显着加快了某些电路的编译和证明生成,并为递归 SNARK 验证铺平了道路。但是,PLONK 的工具目前处于比 Groth16 工具更早的开发阶段,因为证明者的优化程度要低得多,并且在某些系统中尚未实现对高级协议功能的支持。此外,关于 IR 的标准和自定义约束的语言设计还有很多工作要做。AZTEC、Electric Coin Co、iden3、ZK-Garage等团体正在努力构建这些工具。
除了 PLONK 工具链之外,这里还有一些 ZK 开发人员工具的活跃工作领域。